论文链接:https://arxiv.org/pdf/2601.20802
代码链接:https://github.com/lasgroup/SDPO
摘要
大语言模型越来越多地在代码和数学等可验证领域中使用强化学习进行后训练。然而,当前基于可验证奖赏的强化学习(RLVR)方法仅从每次尝试的标量结果奖赏中学习,这造成了严重的奖赏分配瓶颈。许多可验证环境实际上提供了丰富的文本反馈,例如运行时错误或评估结果,这些反馈解释了尝试失败的原因。我们将这种设置形式化为具有丰富反馈的强化学习,并引入了 Self-Distillation Policy Optimization (SDPO)。SDPO 无需任何外部 teacher 或显式奖赏模型,即可将 token 化的反馈转换为密集的学习信号。SDPO 将当前模型在反馈条件下视为 self-teacher,并将反馈指导下的下一个 token 预测蒸馏回策略。通过这种方式,SDPO 利用了模型在上下文中回顾性地识别自身错误的能力。在 LiveCodeBench v6 上的科学推理、工具使用和竞技编程测试中,SDPO 相较于强大的 RLVR 基线方法,提高了样本效率和最终准确率。值得注意的是,SDPO 在仅返回标量反馈的标准 RLVR 环境中也优于基线方法,因为它将成功的尝试作为失败尝试的隐式反馈。最后,在测试时将 SDPO 应用于单个问题可以加速对难度较高的二元奖赏任务的发现,在尝试次数减少 3 倍的情况下,达到与 k 次最佳抽样或多轮对话相同的发现概率。
1.介绍
深度强化学习的进展表明,通过迭代经验(行动、接收反馈并更新策略)可以解锁仅靠静态监督难以获得的能力。同样的道理也出现在大语言模型(LLM)中:大规模的强化学习(RL)后训练显著提升了模型在推理密集型任务上的性能,尤其是在具有程序化或其他可验证评估的场景下。
然而,目前主流的 LLM 后训练强化学习方法仍然受限于奖赏分配机制。大多数现有方法都基于可验证奖赏的强化学习(RLVR):给定一个问题 ,模型采样一个答案 ,并获得一个标量奖赏 ,该奖赏通常是二元的(例如,代码生成中的单元测试通过/失败)。现代策略梯度 RLVR 方法,例如组相对策略优化(GRPO),会根据这些稀疏的奖赏结果来估计优势。此外,当组内所有迭代都获得相同的(通常为零)奖赏时,GRPO 的优势会趋于零,学习过程也会停滞。为了克服这种稀疏性,人们可能会倾向于从强大的教师那里进行提炼,因为强大的教师能够提供密集的、token 级别的监督。然而,在在线学习中,强大的教师往往难以获得,而在线学习的目标是将能力上限提升到现有模型之上。
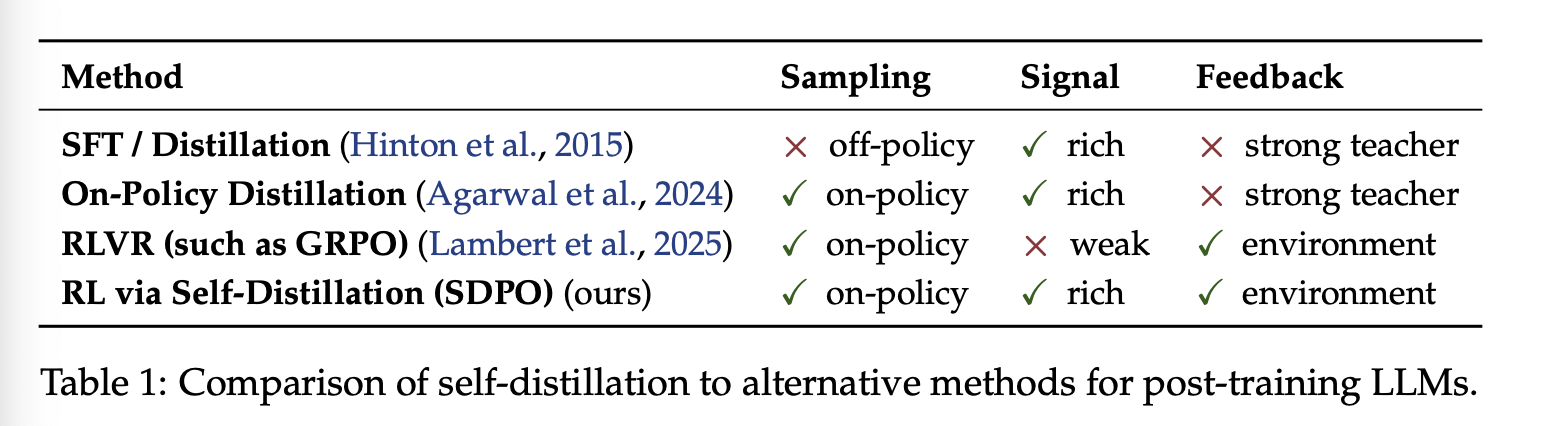
本文认为,关键的限制并非强化学习本身,而是标量结果奖赏所造成的信息瓶颈。许多可验证的环境除了标量奖赏 之外,还会提供丰富的 token 化反馈,例如运行时错误、失败的单元测试或来自 LLM 的评估。这些反馈不仅揭示了部署是否失败,还指出了失败的原因。我们将这种更一般的设置形式化为具有丰富反馈的强化学习(Reinforcement Learning with Rich Feedback,RLRF),并在图 2 中展示了它与 RLVR 的区别。在这里,反馈可以是智能体系统达到的任何状态的任何 token 化表示。核心问题在于:如何在无需强大教师的外部监督的情况下,将丰富的反馈转化为有效的评分分配?
我们的出发点是观察到 LLM 本身就具备一种强大的反馈机制:上下文学习。当模型接受反馈后,通常能够识别出合理的错误并提出修正方案。LeetCode 等编程平台上的失败测试用例总结就是一个常见的例子(图 3)。许多近期研究都利用这种能力来迭代地生成修正方案。与此不同,我们将当前策略用作 self-teacher,它并非采样新的响应,而是在收到丰富的反馈后重新评估现有的方案。上下文反馈的引入改变了模型的下一个 token 分布,使得 self-teacher 能够在特定 token 上对 stduent 的初始选择表示赞同或反对。这最终实现了密集的、logit 级别的分数分配。
例如,当获得图 3 中的反馈时,self-teacher 可以确定如何修改初始尝试以避免运行时错误。至关重要的是,这种机制不会产生任何采样开销:我们只需在 self-teacher 的反馈增强上下文中重新计算原始尝试的对数概率即可。
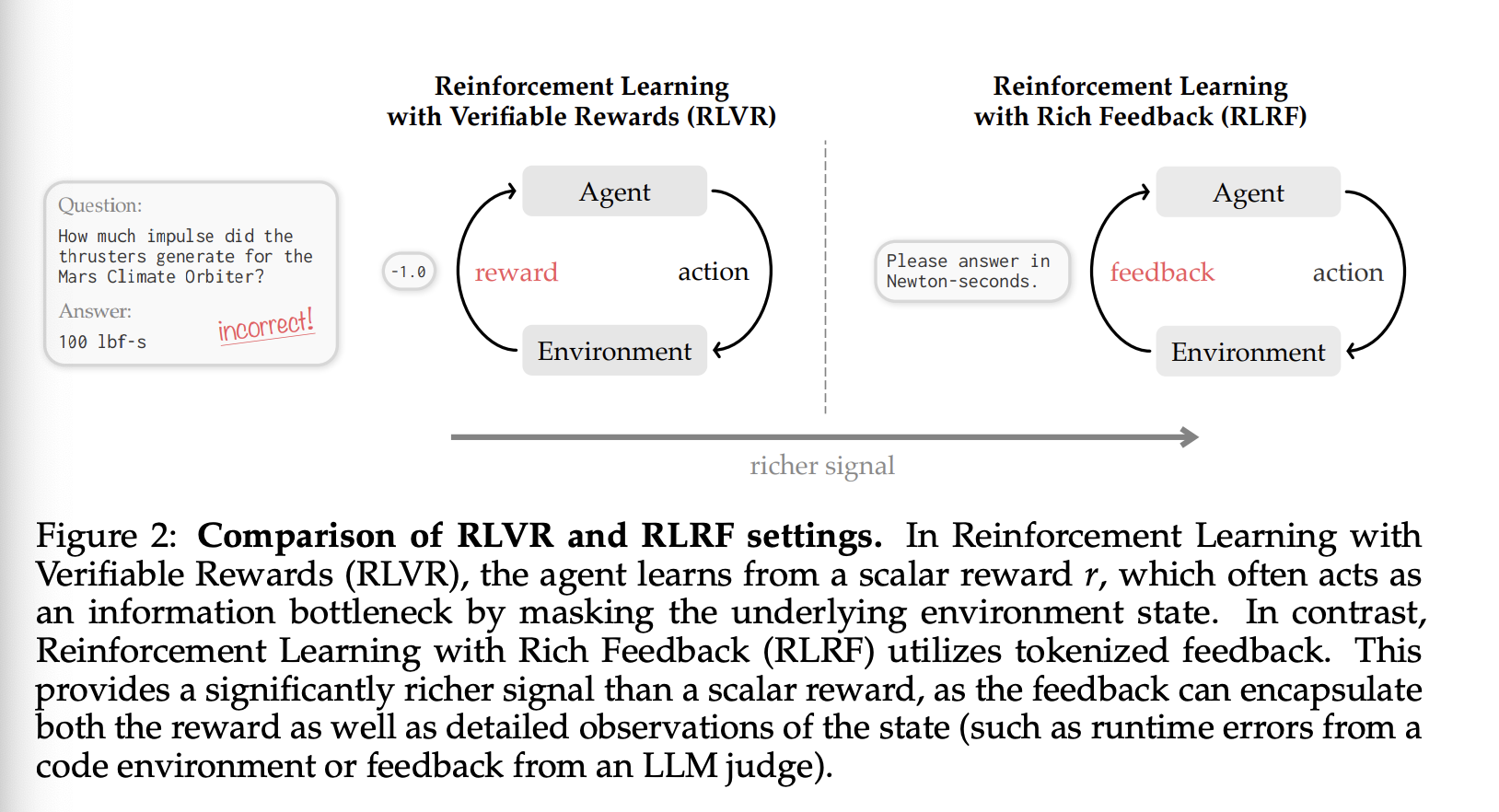
基于此思路,我们提出了 Self-Distillation Policy Optimization (SDPO),这是一种基于策略的算法,它通过自蒸馏进行强化学习。SDPO 从当前策略中采样展开结果,获取丰富的环境反馈,然后最小化一个 logit-level 的蒸馏损失,该损失使当前策略的下一个 token 分布与 self-teacher 的分布相匹配。从概念上讲,SDPO 解决了将蒸馏应用于在线学习的核心限制:缺乏更强大的外部教师。SDPO 不依赖于固定的教师,而是利用模型事后识别自身错误的能力。通过将当前策略与刚刚接收到的丰富反馈进行条件化,我们构建了一个 self-teacher,它既提供了蒸馏的密集监督,又保留了基于策略的强化学习的探索优势。表 1 总结了 SDPO 相对于 RLVR 和蒸馏基线算法的定位。我们在第 6 节中对相关工作进行了全面的总结。
我们证明 SDPO 是一种策略梯度算法,其优势值是通过 self-teacher 估计的。这使得只需对标准 RLVR 流程进行少量修改(例如替换优势值),即可实现 SDPO。
Summary of evaluation results。我们在三种在线强化学习环境中评估了 SDPO:
- Learning without rich feedback (§3):我们评估了标准的 RLVR 环境,这些环境除了标量奖赏外不提供任何反馈。在此环境中,SDPO 将当前批次中采样到的成功尝试视为对同一问题失败尝试的“反馈”。我们首先使用 Qwen3-8B 和 Olmo3-7B-Instruct 数据集进行科学推理和工具使用方面的训练。我们发现,SDPO 的性能优于整合了最新改进的强基线 GRPO:总体最终准确率分别为 68.8% 和 64.1%。与 GRPO 相比,SDPO 在生成长度最多缩短 7 倍的情况下仍能实现更高的准确率,这表明有效的推理并不一定需要冗长。
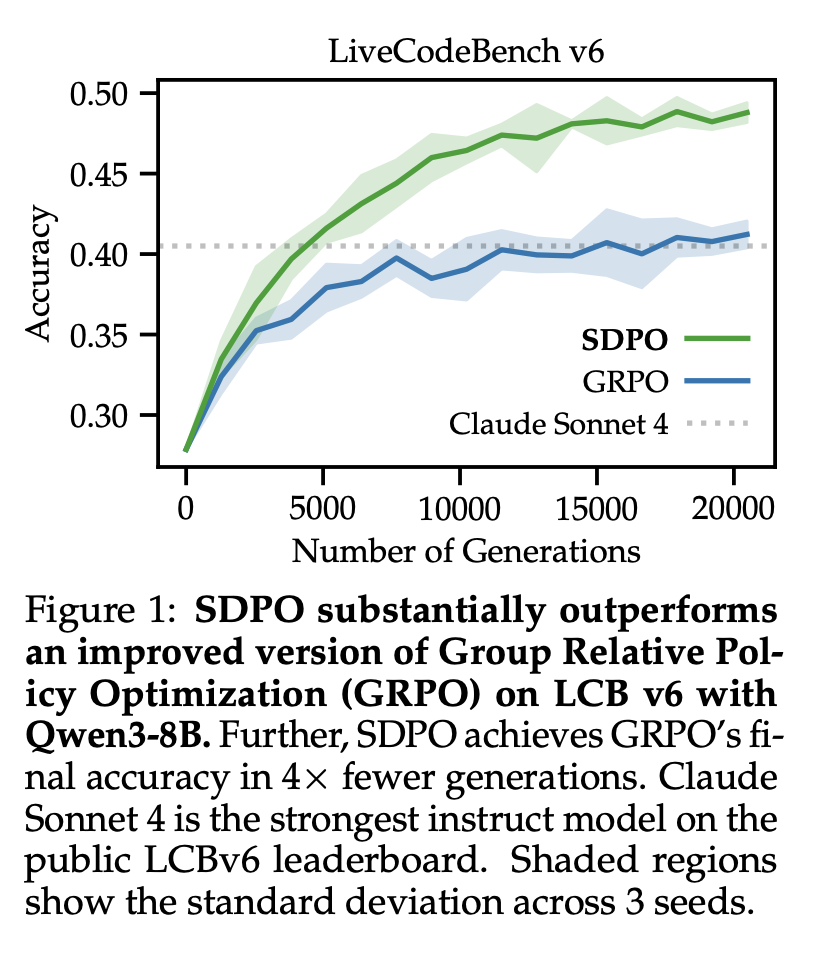
- Learning with rich feedback (§4):我们使用类似 LeetCode 的反馈机制评估 LiveCodeBench v6 中的编程竞赛题目。如图 1 所示,SDPO 相较于 GRPO 有显著提升,最终准确率更高(48.8% 对比 41.2%),并且仅需 GRPO 四分之一的迭代次数即可达到相同的最终准确率。SDPO 的性能提升随着模型规模的扩大而增加,这表明随着模型在上下文中学习能力的增强,其自学习能力也随之增强。
- Discovering novel solutions to hard tasks at test-time (§5):最后,我们证明 SDPO 可以加速发现难二元奖赏问题的解决方案。这与 RLVR 方法形成鲜明对比,后者只有在找到第一个解决方案后才开始学习。我们利用 SDPO 进行测试时自蒸馏,这是一种测试时训练形式,其中模型针对特定测试问题进行专门化。我们考虑了难度极高的 LiveCodeBench 问题,对于这些问题,基础模型的 pass@64 低于 0.03,结果表明 SDPO 将解决方案的发现速度提高了 3 倍。

2.SDPO: Self-Distillation Policy Optimization

我们提出了一种算法,该算法利用当前策略的上下文学习能力来分配分数。我们的核心对象是 self-teacher ,它指的是当前策略(“student”)在问题 和丰富反馈 的提示下的行为。除了学生的初始尝试 之外, 还可以包含两种关键的反馈:1)任何环境输出(例如代码环境中的运行时错误);2)以及如果 已在 rollout 组中通过其他尝试解决,则提供的示例解决方案。如前所述,self-teacher 的准确率应该高于 student 。因为它能够获取额外的上下文信息。由此我们可以观察到:
We can use the same policy in two different roles: As the student for the initial attempt and as the teacher to determine the value of actions in hindsight.
我们引入了 Self-Distillation Policy Optimization (SDPO),它反复地将 self-teacher 模型蒸馏成 student 模型。给定一个问题 ,我们首先从学生模型 中采样 rollout 结果,并获得相应的环境反馈。然后,我们使用 KL 散度 作为学生和教师模型下一 token 分布的距离度量,并优化一个标准的 logit 蒸馏损失:
Stopgrad 算子阻止梯度流经 teacher,从而防止 teacher 回归到 student 并忽略反馈 。teacher 的直观作用是基于反馈 进行回顾,从而确定学生最初的尝试 出错的地方和方式。图 4 展示了一个以 Qwen3-8B 作为 student 和 self-teacher 的自学示例。我们在算法 1 中总结了 SDPO,并在表 2 中展示了 teacher 的提示模板。

我们可以按如下方式推导出 SDPO 梯度(详见附录 B.1):
Proposition 2.1。令 词表中 token 的集合。 的梯度为:

2.1 Comparison to RLVR
注意,SDPO 梯度是一个负的 logit-level 策略梯度,其中优势值是使用 self-teacher 估计的。因此,我们可以重用标准的 RLVR 实现,只需替换优势值即可。令 为问题 的大小为 G 的 rollout 组中的第 个 rollout,则有:
对于词表内任何非生成的 token,GRPO 的优势为零,且在展开 内保持不变。相反,SDPO 的优势仅在 student 和 teacher 完全一致的 token 上为零。对于更有可能由 teacher 生成的 token,SDPO 的优势为正;而对于不太可能由教师生成的 token,SDPO 的优势为负。因此,SDPO 可以从两个方面被视为标准 RLVR 方法的直接扩展:
- 从 1-bit 反馈到允许任意序列的 token 作为反馈,以及
- 利用这些丰富的反馈来估计密集 logit-level 优势。
与 RLVR 方法的紧密联系也使得通过 PPO 式裁剪重要性采样将 SDPO 梯度从公式(2)直接扩展到 off-policy 数据成为可能,参见附录 A.3。
2.2 Compute time & memory
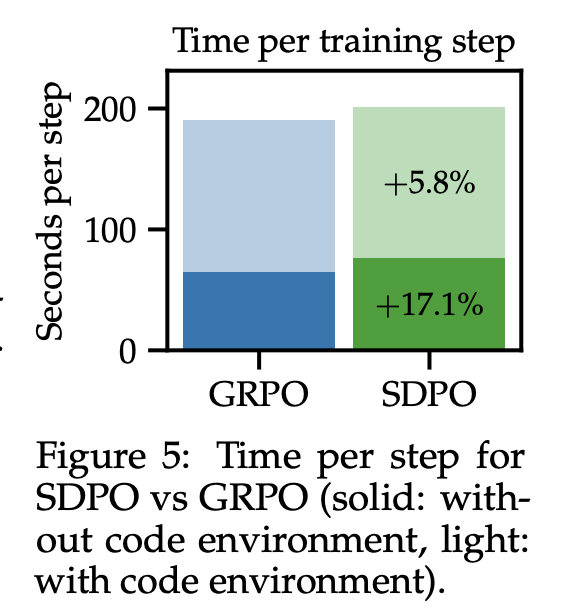
与 GRPO 相比,SDPO 唯一的计算开销在于需要额外计算 self-teacher 的对数概率,而这部分计算可以有效地并行化,并且比顺序生成快得多。图 5 对比了 SDPO 和 GRPO 的计算时间。正如预期的那样,SDPO 的计算开销相对较小。这里我们使用的 micro batch size 为 2;通过使用更大的 micro batch size,计算时间可以进一步减少。
直接计算 student 模型和 teacher 模型之间的 KL 散度需要将两个模型的全部 logits 值都保存在内存中。为了避免这种情况,我们通过执行 top-K 个 logits 蒸馏(即仅计算 student 模型的 top-K 个 logits 值以及 teacher 模型的对应 logits 值,并加上一个用于捕捉尾部概率的项;参见附录 A.2)来近似 SDPO 损失中的 KL 散度。当 K 值选择合理时(例如 K = 100),这种方法几乎不会增加任何内存开销,同时又能保留大部分信息。
2.3 Stability improvements
我们发现,两项实用改进显著提升了 SDPO 的训练稳定性。首先,我们采用了一种正则化的 self-teacher 方法,该方法可以通过对 student 参数进行指数移动平均(EMA)或将当前 teacher 与初始 teacher 进行插值来实现(参见附录A.1)。正如后文详述,这两种策略都能有效稳定学习过程。其次,我们采用对称的 Jensen-Shannon 散度作为蒸馏损失函数;已有研究表明,这种方法同样能够提高基于外部 teacher 的策略蒸馏的稳定性。
3.Learning without Rich Environment Feedback
我们首先在标准的 RLVR 环境中评估 SDPO,该环境中的反馈仅限于标量奖赏。SDPO 不采用标量奖赏,而是将当前 batch 中抽取的成功尝试作为同一问题失败尝试的“反馈”。通过将 student 的尝试与正确答案进行比较,self-teacher 可以识别 student 的错误之处,并进行密集的评分。
3.1 Experimental setting
我们评估未经模型显式微调的任务:
- Science Q&A:使用 SciKnowEval 中的推理子集 (L3) 进行本科生水平的科学推理。
- Tool use:使用 ToolAlpaca 将工具 API 规范和用户请求映射到正确的工具调用。
我们进行训练集和测试集划分,以测试领域内泛化能力。我们使用 Qwen3-8B 和 Olmo3-7B-Instruct 作为初始 checkpoint,并报告相对于实际训练时间(不包括初始化和验证)的 avg@16 效果。
Baselines。我们将 SDPO 与 GRPO 的改进变体进行比较,后者融合了多项最新改进,例如非对称裁剪、避免有偏归一化以及在使用高效推理框架时校正离策略数据。我们将这些改进集成到 GRPO 实现中,该实现构成了一个强大的基线,详见附录 A.3 中的公式 (8)。GRPO 通过 PPO 的裁剪重要性加权实现 off-policy 训练。此外,我们还报告了 on-policy GRPO 的特殊情况(其超参数与原始 SDPO 相匹配)。对于两个基线模型,我们进行超参数扫描,并报告在所有目标任务中验证性能最高的模型的结果。超参数和训练细节见附录 E。我们使用 verl 库进行快速多 GPU 训练。
3.2 Results
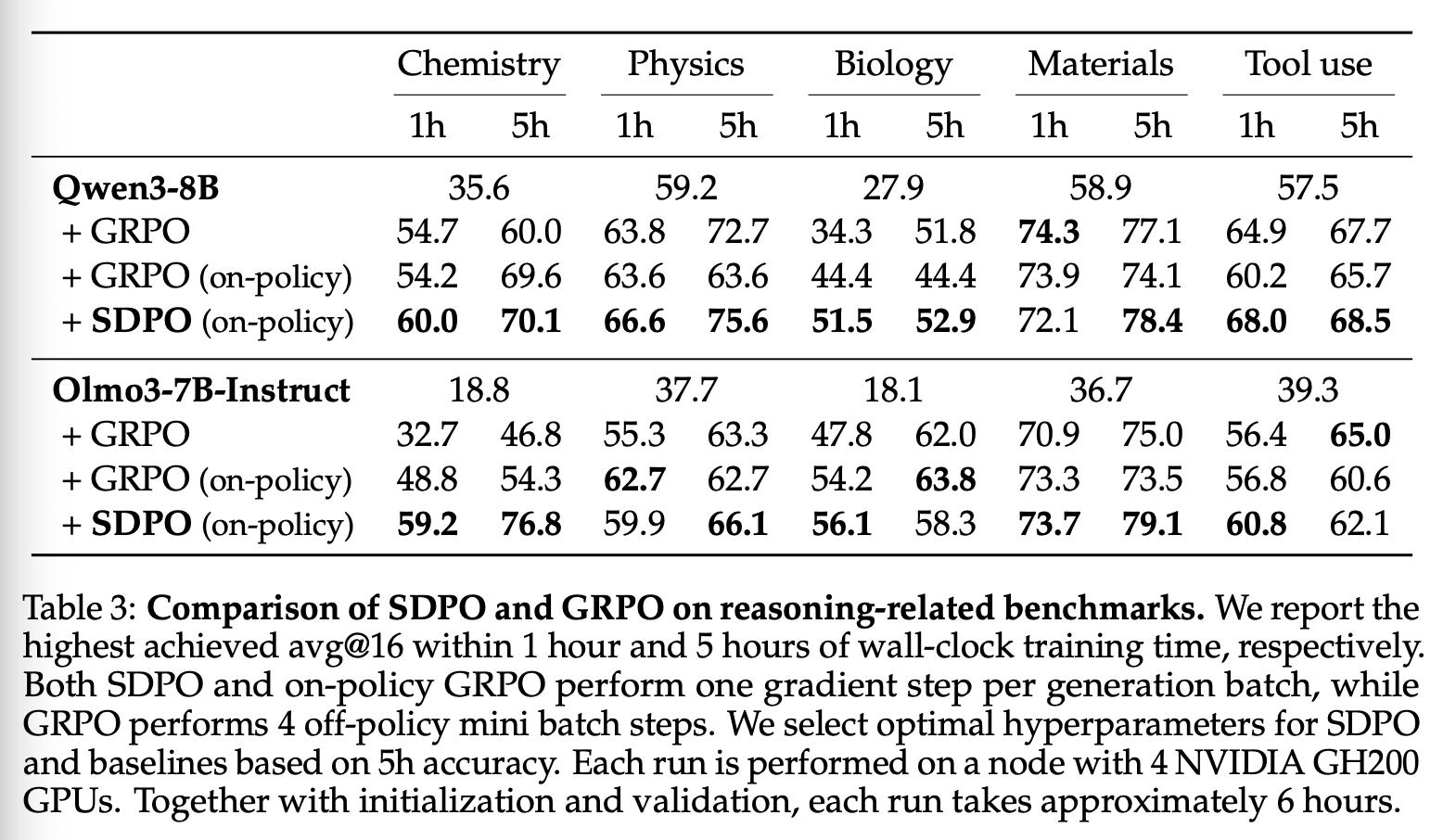
表 3 总结了我们的结果。我们发现,在几乎所有运行中,SDPO 的性能都优于 GRPO,并且通常能带来显著的改进。SDPO 的学习速度明显快于 GRPO,在某些情况下,SDPO 仅需1小时的训练即可达到 GRPO 近5小时的训练速度。如图6(左)所示,SDPO 在化学任务上的表现尤其优于 GRPO。使用 Olmo3-7B-Instruct,SDPO 仅需30分钟的实际训练时间即可达到 GRPO 需要5小时才能达到的准确率,速度提升了 10 倍。此外,SDPO 的5小时准确率比 GRPO 高出20个百分点以上。
我们注意到,我们使用 SDPO 得到的结果严格基于 on-policy 训练(即每个生成 batch 仅进行一次梯度更新)。考虑到 off-policy 方法在每个生成 batch 中执行多次梯度更新所带来的效率提升,我们认为研究采用 off-policy 更新的 SDPO 是一个值得未来深入探索的方向。
Takeaway 1 我们证明,SDPO 能够有效地学习推理,并能泛化到更具挑战性的推理任务中。在无需对现有 RLVR 环境进行任何修改的情况下,SDPO在多个案例中都显著优于 GRPO。
3.3 Self-distillation learns to reason concisely
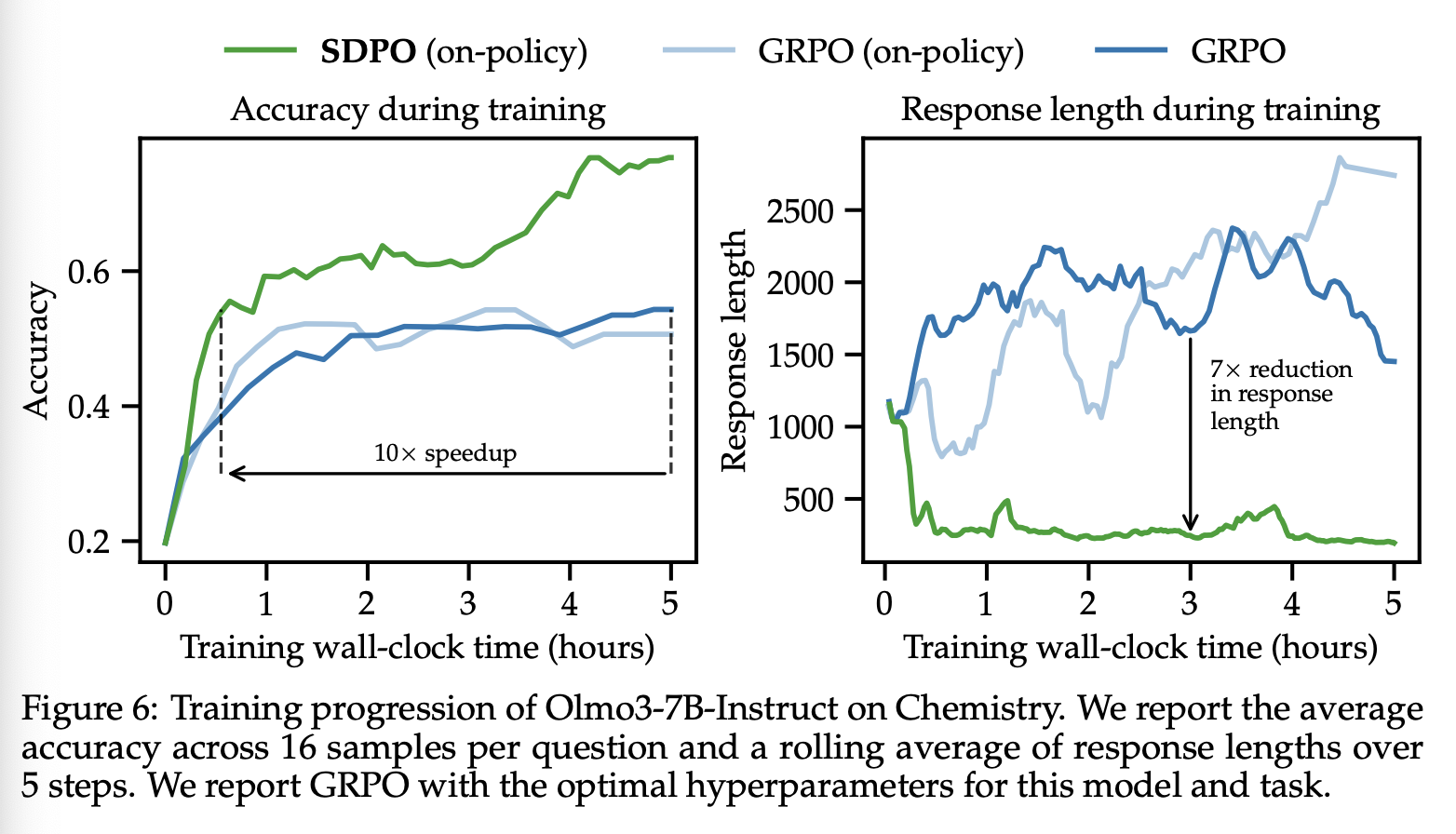
我们始终观察到,SDPO 生成的生成序列比 GRPO 短得多,同时准确率更高。在所有任务中,SDPO 的响应平均比 GRPO 短 3 倍以上(参见附录 D 中的表 8)。在 Olmo3-7B-Instruct 的化学任务中,SDPO 的响应长度甚至比 GRPO 缩短了 7 倍,同时保持了更高的准确率(图 6(右))。尽管 RLVR 的最新进展表明,扩展响应长度是推动推理能力涌现的重要因素,但我们的结果表明,有效的推理并非总是冗长的。我们发现 SDPO 提高了推理效率。
从定性角度来看,我们观察到 GRPO 较长的响应通常源于“肤浅”的推理,而非必要的认知步骤。GRPO 经常生成诸如“嗯”、“等等”之类的填充词,或者陷入循环逻辑,逐字重复之前的步骤。图 7 展示了这一现象的典型示例。值得注意的是,SDPO 的生成过程保持简洁,避免了这些肤浅的模式。这或许可以解释为 SDPO 采用了密集型权重分配机制,它为每个下一个 token 的预测赋予特定的优势,从而产生稀疏的优势(参见附录F中的图21)。通过提高推理效率,SDPO 缩短了推理生成时间,并表明可以通过改进模型的推理方式(而不仅仅是延长推理时间)来提升推理性能。

4.Learning with Rich Environment Feedback
接下来,我们评估 SDPO 在编码任务上的表现。编码是强化学习环境的典型示例,它能提供丰富的反馈,例如运行时错误和失败的单元测试。学习解决这些编码问题需要严格的评分机制,因为 student 必须准确识别错误,才能避免将来重蹈覆辙。LiveCodeBench 提供了一系列竞赛风格的编码问题,难度从简单到竞赛级别不等。我们的评估仅限于 LCB 的最新子集 LCBv6,其中包含 2025 年 2 月至 5 月期间发布的 131 道题。我们考虑一种包含公共单元测试和私有单元测试的设置,这在代码竞赛和 LeetCode 等编码平台上很常见。其中,公共测试用于训练期间的评估,而私有测试用于验证。
我们的实验采用 Qwen3 模型系列,除非另有说明,否则默认使用 Qwen3-8B。我们报告了 4 次 rollout 的平均准确率,并使用了与第 3.1 节所述相同的 GRPO 基线。
Results。图 1 对比了 SDPO 和 GRPO 在 LCBv6 数据集上的学习曲线。我们发现,SDPO 的最终准确率 (48.8%) 显著高于 GRPO (41.2%),同时也优于 LCBv6 公开排行榜上最强的指令模型:Claude Sonnet 4 (40.5%) 和 Claude Opus 4 (39.7%)。此外,SDPO 达到 GRPO 的最终准确率所需的迭代次数仅为 GRPO 的四分之一。附录表 9 中提供了与 GRPO 性能相近的其他 RLVR 基线模型的详细比较。区分 LCB 的简单、中等和困难题目,我们发现 SDPO 在解决中等和困难题目方面明显优于 GRPO(参见附录图 15)。
4.1 Self-distillation benefits from stronger models
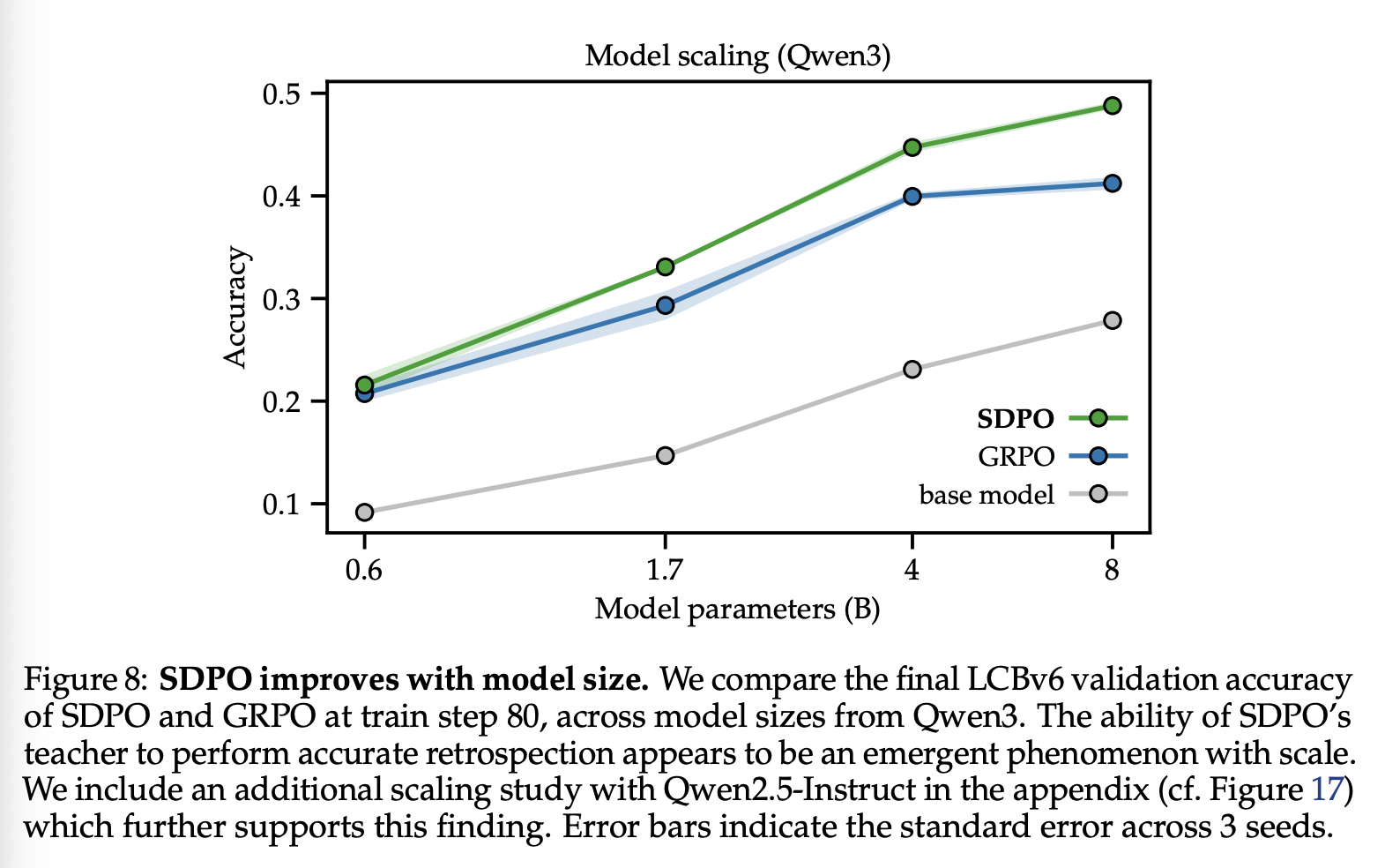
我们工作的核心问题是 SDPO 是否对基础模型的上下文学习能力敏感。直观上,我们预期 SDPO 会受益于强大的上下文学习能力,因为这能让 teacher 进行更准确的回顾。
为了回答这个问题,我们使用 Qwen3 系列的不同模型规模进行了扩展性研究。正如大量先前的研究表明,上下文学习能力会随着模型规模的增大而增强(例如,Brown et al., 2020)。如图 8 所示,SDPO 在较大模型上的性能显著优于 GRPO,而在较小模型上仅略优于 GRPO。为了确定 SDPO 在弱于 Qwen3-0.6B 的模型上是否也会逊于 GRPO,我们使用 Qwen2.5-Instruct 进行了额外的扩展性研究。虽然 SDPO 在 Qwen2.5-7B 上的性能优于 GRPO,在 Qwen2.5-8B 上的性能与 GRPO 相近,但我们发现 SDPO 在 Qwen2.5-1.5B 上的性能逊于 GRPO,如图 17(附录 D)所示。
Takeaway 2 我们的研究结果表明,SDPO 相对于 GRPO 的边际改进与基础模型的强度密切相关,并促使我们未来研究比 Qwen3-8B 更强的模型。正如上下文学习是一种随规模涌现的现象一样,SDPO 中 self-teacher 进行准确回顾的能力似乎也随着规模的扩大而涌现。
4.2 Self-distillation performs dense credit assignment

GRPO 为每个生成的 token 分配一个固定的优势,而 SDPO 则基于 student 和 teacher 的共识,为生成序列中每个可能的下一个 token 分配一个独特的优势。在生成序列 的每个位置 ,都有 个可能的下一个 token,其中 为词表。在知识蒸馏中,这一层级通常被称为 logit-level,因为它对应于模型的 logits 值。实际上,我们用 top-K 个 token 来近似表示完整的下一个 token 分布,因此 SDPO 为每个序列分配 个不同的优势。如图 9 所示,这使得 SDPO 能够执行密集的奖赏分配。
一个自然而然的问题是,SDPO 性能的提升是源于 RLRF 中丰富的反馈机制,还是源于 SDPO 密集的奖赏分配机制。为了回答这个问题,我们针对三种配置对 SDPO 的性能进行了消融测试:
- Logit-level SDPO:在每个位置上,对 100 个最有可能的 token 进行奖赏分配。
- Token-level SDPO:在每个位置上,对最有可能的 token 进行奖赏分配。
- Sequence-level SDPO:我们计算所有生成 token 的 SDPO 优势,并取平均值,从而为每个序列生成一个标量优势(如 GRPO 中那样)。虽然这不会比 GRPO 实现更密集的信用分配,但仍然利用了丰富的反馈 f。
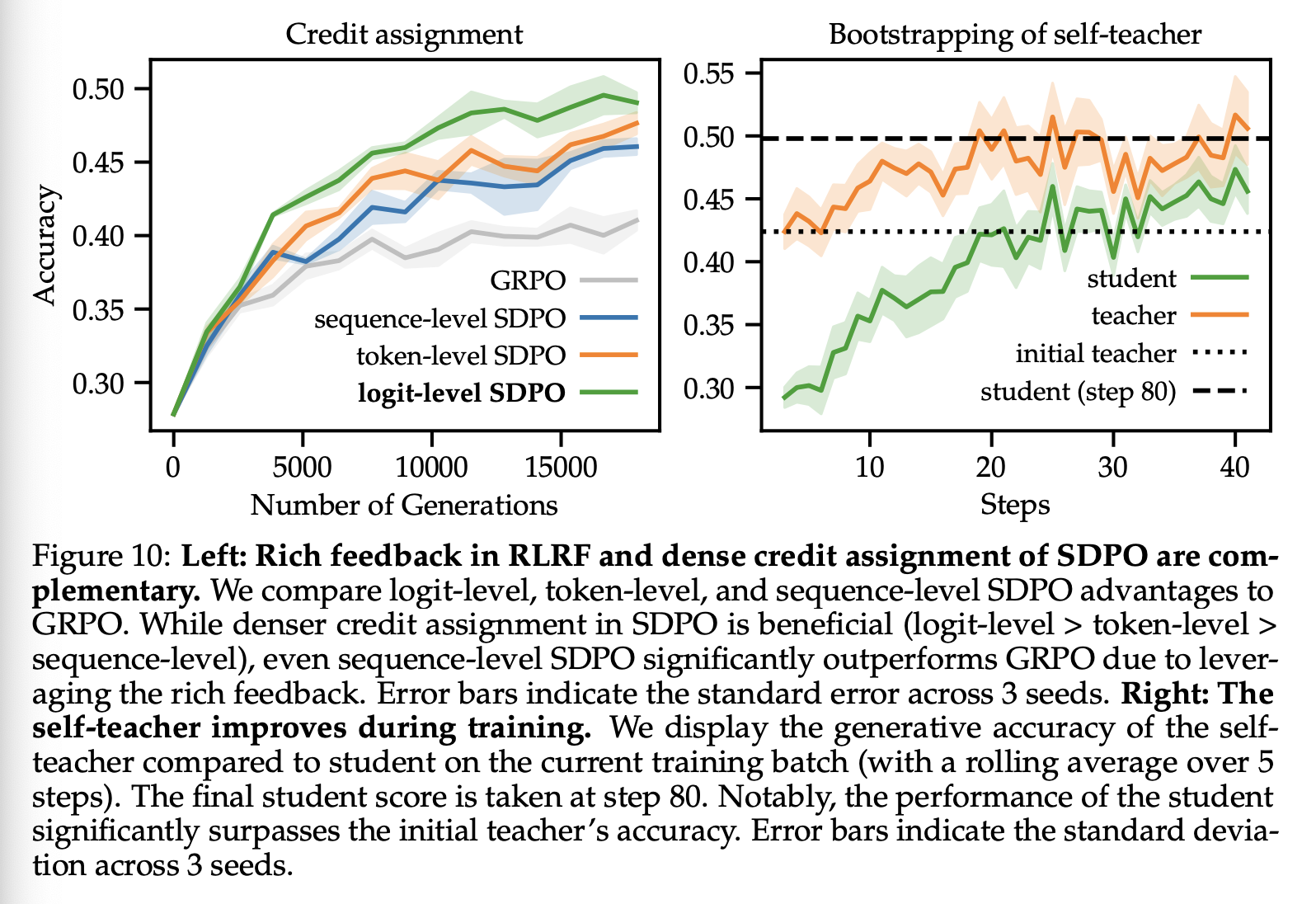
如图 10(左)所示,logit 级 SDPO 的密集奖赏分配相比于 token 级 SDPO 和序列级 SDPO 具有显著的性能提升。然而,即使是序列级 SDPO 也优于 GRPO,这表明即使不采用密集 奖赏 分配,利用 RLRF 中的丰富反馈也能比 RLVR 方法获得显著的性能提升。
4.3 The self-teacher improves during training
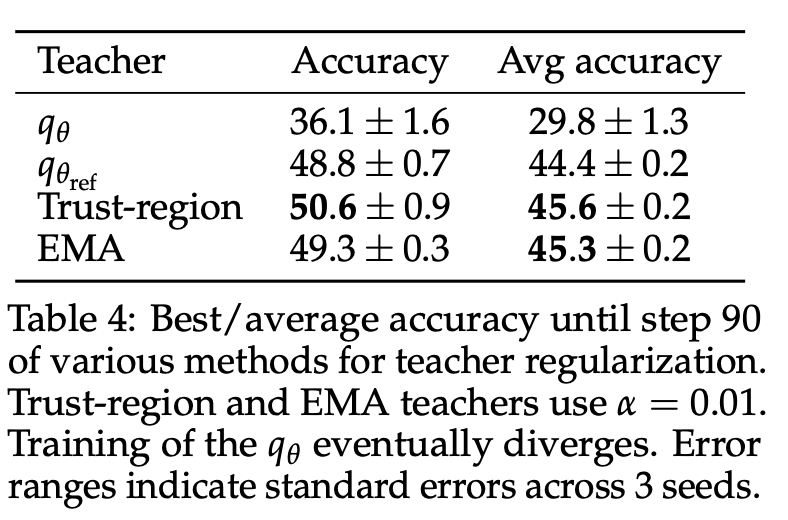
与标准蒸馏不同,SDPO 中的 self-teacher 模型并非固定不变,而是在整个训练过程中不断更新。这是 SDPO 的关键组成部分,因为它使 teacher 模型能够随时间推移而改进,这意味着 student 模型可以从更强的目标模型中学习。为了探究 self-teacher 模型在训练过程中是否有所改进,我们在图 10(右)中绘制了使用 self-teacher 模型生成模型时的平均准确率。我们发现,self-teacher 模型在训练过程中显著改进。尤其值得注意的是,在训练后期,student 模型的准确率超过了初始 teacher 模型的准确率。这表明 SDPO 能够真正实现弱模型到强模型的引导式训练,而不会受到初始 self-teacher 模型性能的限制。
如第 2.3 节所述,SDPO 使用正则化 teacher 来稳定训练。如表 4 所示,非正则化 teacher 的性能显著低于正则化 teacher。此外,信赖域 teacher 和 EMA teacher 的性能优于参数固定的初始 teacher,表明 teacher 可以通过与 studebt 共享参数而得到改进。然而,即使使用参数固定的 teacher,SDPO 也能表现良好。
4.4 On-policy self-distillation avoids catastrophic forgetting
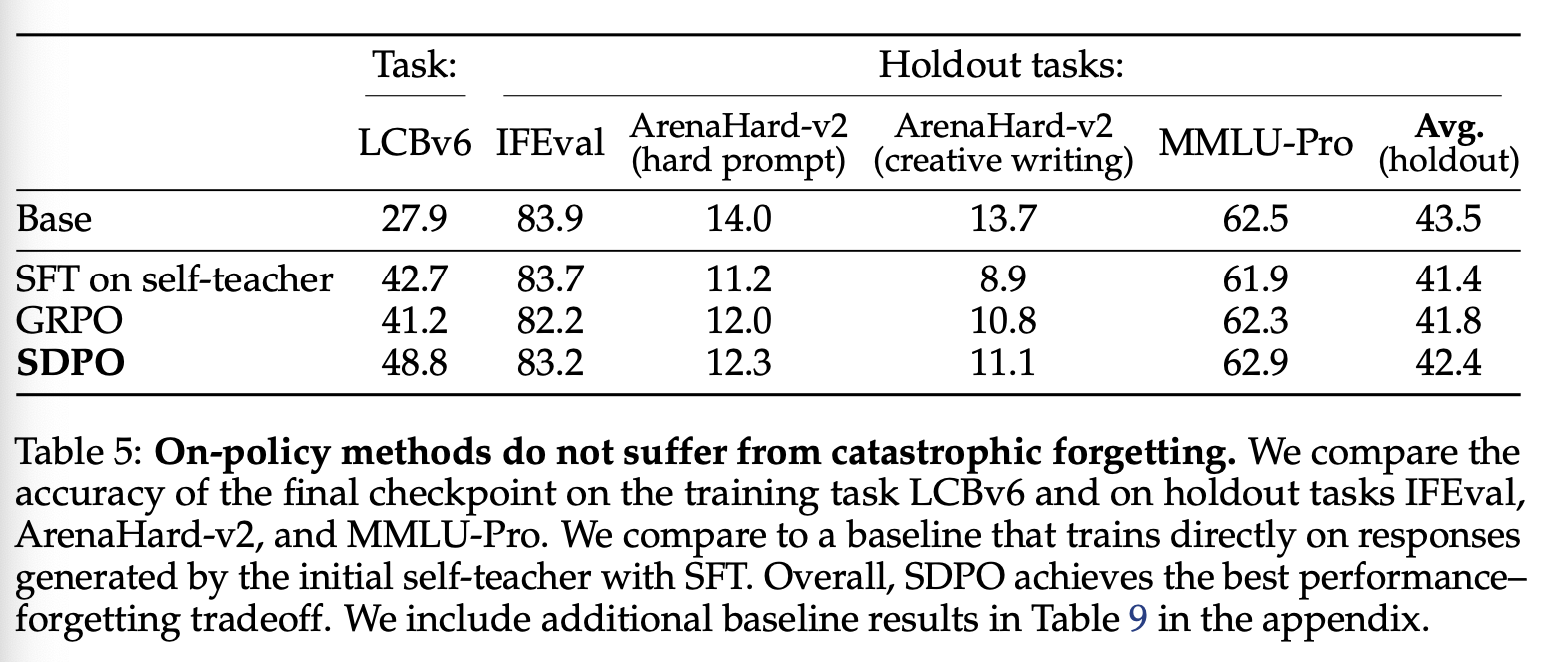
先前的研究表明,on-policy 算法(例如 GRPO)的一个关键优势在于模型不易遗忘先前获得的能力。这在实践中非常理想,因为它支持持续训练流程,模型可以按顺序在各种任务上进行训练,而无需从头开始重新训练。为了评估遗忘情况,我们在不同的保留任务上测试了 GRPO 和 SDPO 的最终检查点:1)IFEval,用于测试模型遵循精确格式指令的能力;2)ArenaHard-v2,这是一个基于 LMArena 的真实世界指令遵循提示的 LLM 评判基准测试;3)以及 MMLU-Pro,用于测试广泛的多任务知识和推理能力。如表 5 所示,SDPO 在学习新任务的同时减轻了初始能力的退化,总体上比 GRPO 实现了更好的性能遗忘权衡。
Off-policy self-distillation baseline。作为额外的基线,我们考虑使用有监督微调(SFT)方法,基于 self-teacher 成功生成的学习样本来训练 student。由于我们需要同时利用 student 和 teacher 的学习样本,因此在相同步数下,SFT 需要两倍于 SDPO 的学习样本。我们报告了基于 self-teacher 成功学习样本的 SFT 训练结果,其准确率高于同时包含学生初始成功学习样本的 SFT 数据。如表 5 所示,基于 self-teacher 的 SFT 在 LCBv6 数据集上的表现显著逊于 SDPO,并且会导致对先前能力的遗忘更为严重。这与先前关于 off-policy 模仿不稳定性的研究结果相吻合(例如,参见 Agarwal et al., 2024)。
4.5 Can GRPO and SDPO be combined?
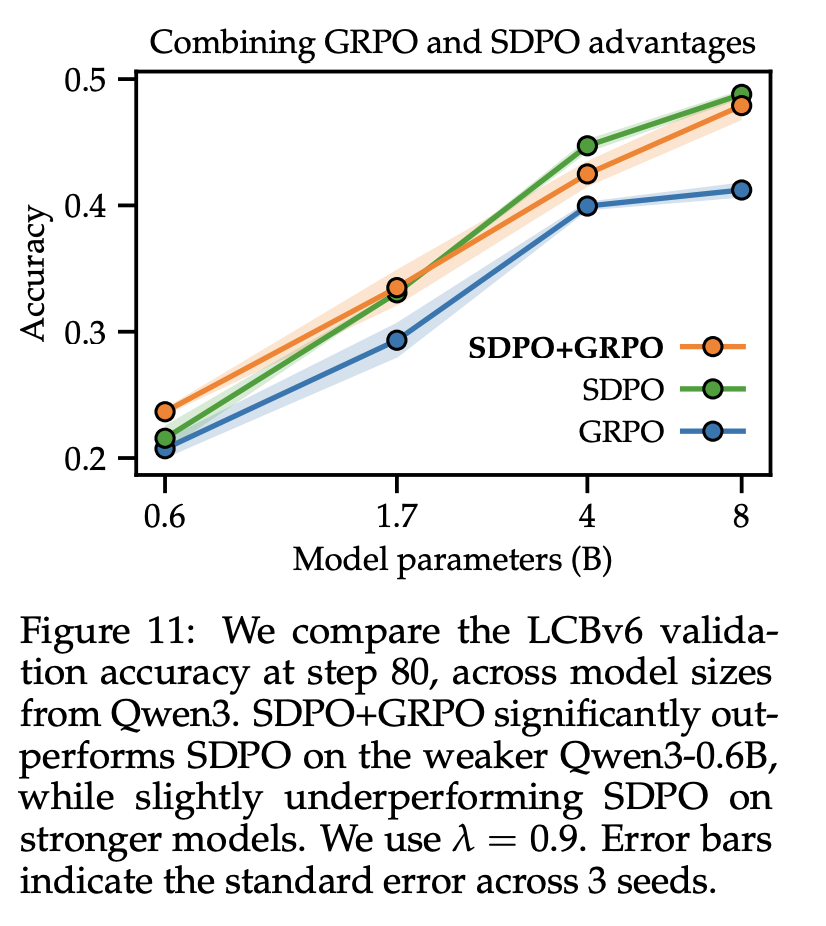
GRPO 利用蒙特卡罗优势,该优势相对于最大化期望奖赏 的目标是无偏的。相比之下,SDPO 优势由于其基于丰富的反馈和自学习过程计算得出,因此本质上相对于 存在偏差。这种二分法类似于强化学习中蒙特卡罗优势和自举优势之间的根本区别:后者虽然存在偏差,但通常方差更低。这促使我们采用一种混合方法,将基于奖赏的 GRPO 优势与基于反馈的 SDPO 优势相结合:
如图 11 所示,SDPO+GRPO 对较弱的模型似乎比 SDPO 更具鲁棒性。直观地说,在像 Qwen3-0.6B 这样的较弱模型中,SDPO 的优势不太可靠,因此引入 GRPO 的优势有助于稳定训练过程。相反,我们发现 SDPO+GRPO 在像 Qwen3-8B 这样的较强模型上的表现略逊于 SDPO。这表明,仅由标量奖赏提供的 GRPO 信号,在初始模型较强的情况下,可能会产生负面影响。
4.6 Which feedback is most informative?
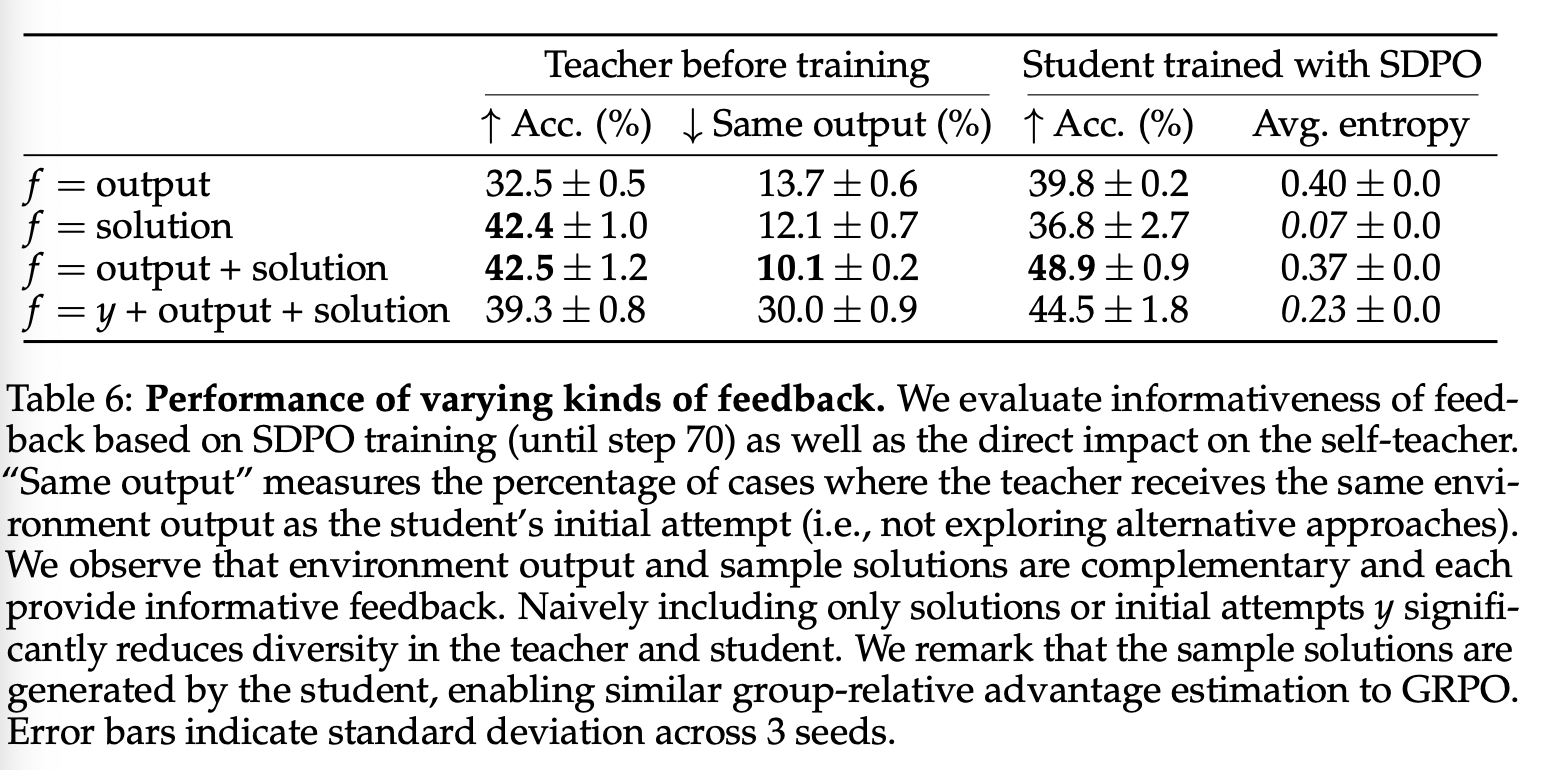
为了解哪种类型的丰富反馈最有信息量,我们对代码生成等可验证环境中存在的三种反馈类型进行消融研究:示例解决方案(如果当前发布组中有成功的发布)、环境输出(例如运行时错误)和 student 的原始尝试。
Sample solutions。包含失败尝试 rollout 组中的示例解决方案(如有)与 GRPO 的群体相对优势非常相似。我们强调,这些示例解决方案始终由 student 生成,与 GRPO 相同,无需专家模型。如果模型已经能够解决问题,这些示例解决方案可以有效抑制失败的尝试。然而,与 GRPO 中所有 token 都获得相同负面优势不同,self-teacher 可以识别具体错误并提供如何改正的反馈。
Environment output。环境输出描述了 student 尝试后环境的状态。这与示例解决方案相辅相成,因为即使 student 之前从未解决过该问题(我们将在第 5 节中对此进行深入探讨),环境输出也能提供有用的信息。利用环境输出是 RLRF 和 RLVR 设置之间的一个关键区别因素。
Student’s original attempt。学生最初的尝试 不必包含在 teacher 的重新提示模板中。事实上,我们发现,将其包含在模板中会使teacher 倾向于采用 student 的尝试(参见表 6)。这会降低学生分布的熵(特别是对于最初不确定的 token),从而减少探索行为。
我们在表 6 中总结了结果,评估了其对 SDPO 训练的影响以及对 self-teacher 的直接影响。我们发现环境输出和示例解答是互补的,两者都提供了有用的反馈。总体而言,我们观察到,表 2 中提示模板的句法变化对学习效果并不敏感。
5.Solving Hard Questions via Test-Time Self-Distillation

在第 3 节和第 4 节中,我们已经证明,在对推理任务执行 train-time RL 时,SDPO 可以比 RLVR 方法有显著的改进。现在,我们转向测试时设置,其中模型仅被赋予一个困难的(二元奖赏)问题 ,并且必须尽快找到解决方案:
Definition 5.1 (Discovery time)。发现时间是指找到解决方案所需的试验次数(即,第 次尝试 获得奖赏 1 的最小 k 值)。
基于这一概念,我们可以定义一个衡量发现效率的指标:
其中概率是针对算法中产生 和奖赏的任何随机性而言的。因此, 指标量化了在 步内发现解决方案的概率(我们提出的 指标是运行时加速研究中的一个典型指标,即终止时间)。虽然先前的研究已经探讨了使用连续奖赏进行 discovery 的问题,但在稀疏或二元奖赏设置下,使用语言模型进行 discovery 的问题无法通过“爬山”算法来获取连续奖赏,因此其机制仍未被充分理解。
在二元奖赏任务中,最简单的 discovery 方法是从基础模型中重复进行独立同分布(i.i.d.)采样,也称为 best-of-k 方法。best-of-k 采样的标准 指标恰好是从一个固定模型中独立抽取 k 个样本并发现至少一个解的概率,这与 指标一致。 指标将 推广到顺序采样算法。一种常见的顺序采样方法是利用先前尝试的额外上下文信息重新提示基础模型。我们称之为多轮采样。在这种方法中,模型本身不会改变,只有其上下文信息会随时间演变。
对问题 执行 RLVR 并不能比对基础模型进行 best-of-k 采样有所改进,因为二元奖赏在找到第一个解之前无法提供任何信号。而像 SDPO 这样的 RLRF 方法则不存在同样的限制,因为它在每次尝试后都能从环境中获得丰富的反馈。这种丰富的反馈使得模型能够在遇到错误并获得反馈后反复“纠正”错误,甚至在找到解之前就能做到这一点。与多轮采样不同,SDPO 通过将 蒸馏成模型 来反复压缩上下文 ,如图 12 所示。这种自蒸馏使得 SDPO 能够在较长的上下文中持续学习,而 Transformer 的内存瓶颈则固有地限制了多轮采样的上下文长度。在本节中,我们试图回答以下问题:
通过自蒸馏反复将上下文压缩到模型权重中,能否加速难题的发现?
5.1 Experimental setting
我们选取了 LCBv6 中一个难度极高的子集问题,这些问题达到了 Qwen3-8B 的性能上限,需要大量的测试时间采样才能找到任何解。具体来说,我们使用 Qwen3-8B 的 pass@k 值将问题分为两组:pass@64 < 0.5 的难题和 pass@64 < 0.03 的极难难题。在这些难题中,我们保留了那些在 5 个种子点下,使用任何一种方法(例如 best-of-k、多轮迭代或SDPO)都能在512步内找到至少一个解的问题。最终得到 19 道难题和 9 道极难难题。
对于基础模型下的 best-of-k 采样,我们报告了来自 2944 次独立 rollout 的标准 pass@k 估计值。作为多轮采样,我们使用先前尝试的串联反馈,按顺序在上下文中重新提示模型。为了保持在 Qwen3-8B 的 40k 个token的上下文限制内,我们采用先进先出(FIFO)的滑动窗口,一旦达到最大提示长度(32k个token),就丢弃最早的反馈。我们在附录D的图 19 中消融了多轮重新提示策略,发现仅保留过去的反馈而忽略早期尝试显著优于同时保留过去尝试的基线模型。我们使用 batch size 为 16 评估 SDPO。我们在附录D的图 19 中消融了这一选择,发现总体性能差异很小,但较小的 batch size 有利于在低生成预算下改进,而较大的 batch size 则会带来更稳定的更新,即使在运行后期也能学习解决问题。
5.2 Results
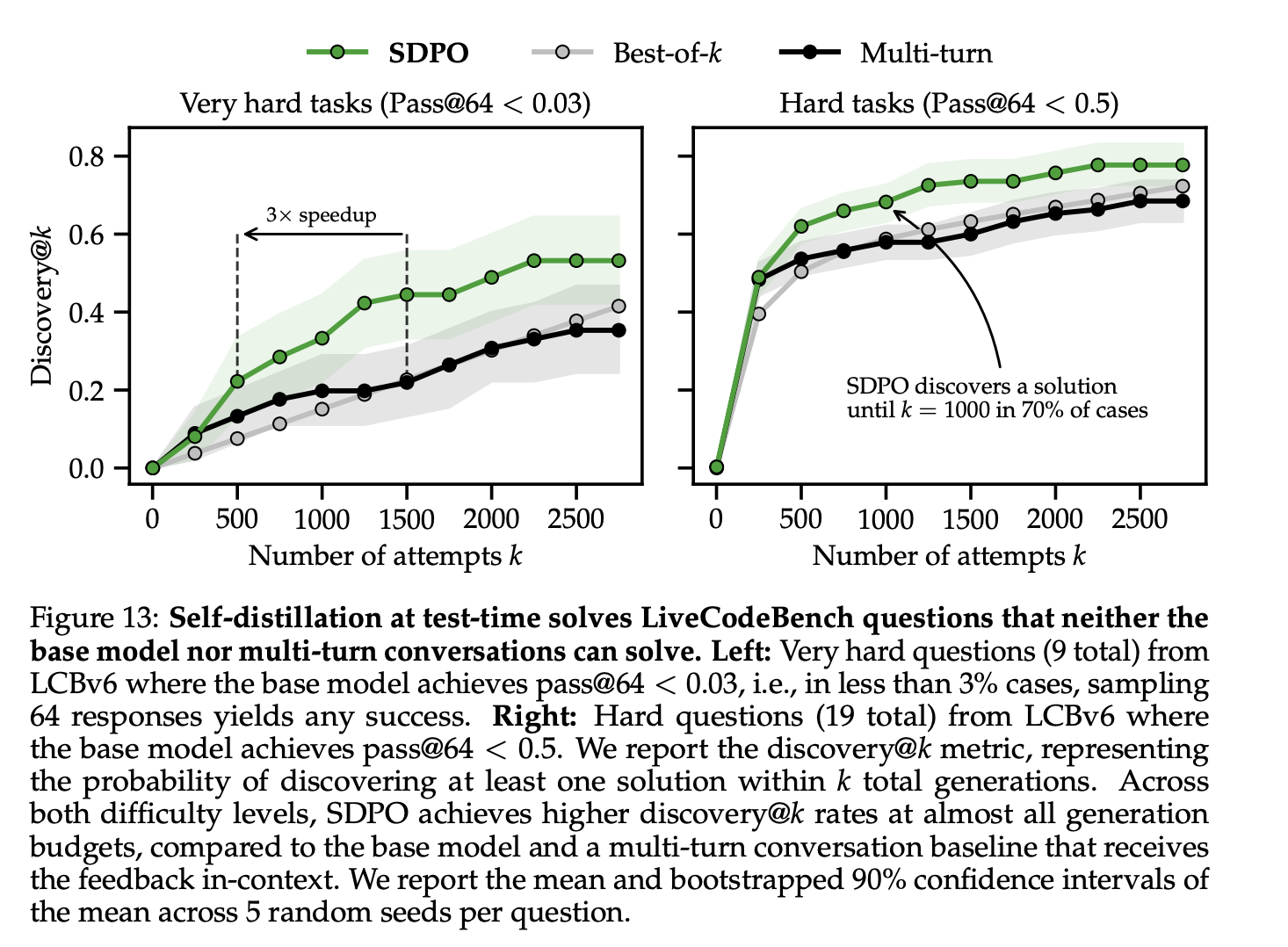 图 13 比较了 SDPO、多轮抽样和 best-of-k 抽样在 LCBv6 的极难(左)和难(右)题目上的 discovery@k 值。在两种难度级别下,SDPO 在几乎所有生成预算下都实现了显著更高的 discovery@k 值。
图 13 比较了 SDPO、多轮抽样和 best-of-k 抽样在 LCBv6 的极难(左)和难(右)题目上的 discovery@k 值。在两种难度级别下,SDPO 在几乎所有生成预算下都实现了显著更高的 discovery@k 值。
在难度极高的任务上,多轮迭代和 best-of-k 迭代算法在可用迭代次数预算内大多无法解决问题,其在 discovery@2750 上的通过率分别仅为 35.6% 和 41.5%,而 SDPO 算法在 53.2% 的情况下都能找到解决方案。SDPO不仅总体上解决了更多的问题,而且所需的迭代次数也显著减少。值得注意的是,在难度极高的问题上,SDPO达到22%的发现概率所需的迭代次数比k次最佳迭代和多轮迭代少约3倍。在难度较高的任务上,SDPO 在 discovery@2750 上的通过率达到了78%,而达到 67% 的通过率所需的迭代次数比 best-of-k 迭代和多轮迭代少约 2.4 倍。总体而言,多轮迭代和 best-of-k 迭代分别只能解决 68.4% 和 72.3% 的问题。对于困难的问题,多轮采样的上下文窗口长度在 837 (±466) 步后达到;对于非常困难的问题,在 1007 (±349) 步后达到。这或许可以解释为什么在高生成预算下,其收益会递减。
Question 3 is only solved by SDPO。SDPO 解决了所有通过 best-of-k 抽样和多轮抽样都能解决的问题。此外,SDPO 还唯一地找到了 Q3 的解,该解在 2750 次尝试内既无法通过多轮抽样也无法通过 k 值最优抽样解决。相比之下,SDPO 在 321 次尝试后才首次找到 Q3 的解,这相当于基于反馈的自蒸馏算法进行了 20 次迭代,每次迭代的 batch size 为 16。我们在附录 D 的表 10 中列出了每个问题的详细结果。
The initial self-teacher does not solve hard questions。值得注意的是,self-teacher 的初始准确率几乎在所有问题上都低于 1%,甚至有 78% 的问题准确率完全为 0%(见附录 D 表 11)。这表明,单次上下文反馈不足以解决问题。尽管如此,self-teacher 的评分机制足以让 SDPO 迭代改进策略,最终解决这些问题。
我们证明,丰富的环境反馈能够使 SDPO 显著加速难题的发现。这与 RLVR 方法形成鲜明对比,后者仅接收二元奖赏信号,因此只有在找到第一个解之后才开始学习。
6.Related Work
A Implementation of SDPO
图 14 中的以下伪代码概述了 SDPO 的实现:

以下我们将提供更多详细信息:
- Teacher 正则化 (Appendix A.1)
- 使用 top-K 个 logits 近似 logits 蒸馏以节省 GPU 内存 (Appendix A.2)
- 将 PPO 风格的策略梯度算法推广到 logit-level 优势 (Appendix A.3)
为了消除 self-teacher 符号的歧义,我们在下文中使用 。其中,reprompt 表示self-teacher 的 reprompt 模板。
A.1 Regularized teacher
与标准蒸馏不同,SDPO 中的 teacher 模型在训练过程中会不断变化。这种自举机制使得 teacher 模型能够不断改进,但也可能导致训练不稳定。为了稳定训练,我们力求防止 teacher 模型 快速偏离初始教师模型 。我们可以通过对 施加显式的信赖域约束来实现这一点,即:
这种信赖域可以通过两种方式实现:
- Explicit trust-region:我们可以将 teacher 策略定义为在满足信赖域约束的前提下,最接近 的策略。该 teacher 策略可以表示为
其中 为信赖域约束的拉格朗日乘子的逆函数。完整的推导过程见附录 B.2。我们可以将这个显式约束的 teacher 模型直接代入 SDPO 目标函数中。 3. Exponential moving average (EMA):或者,我们可以直接稳定 tehacher 的参数;用 参数化 ,并更新为 ,其中 。在温和的平滑性假设下,该 EMA 教师隐式地保持在初始教师周围的信赖域内(参见附录 B.3)。
需要注意的是,每种实现方式各有优势:EMA teacher 模型需要额外的 GPU 内存来计算 ,但不会增加任何运行时开销。相比之下,信赖域 teacher 模型需要使用 进行额外的对数概率计算,但如果 用于显式 KL 正则化,则不需要额外的 GPU 内存。
A.2 Approximate Logit Distillation
为了节省 GPU 内存,我们仅对 student 预测的 top-K 个 token 进行蒸馏:

这里,top-K 个 token 是针对 student 而言的。如果没有 top-k 个 token 蒸馏,我们就需要在内存中保存两份 logits 数据:一份用于 teacher,一份用于 student。由于词表中的大多数 token 在给定时间点上并不具有信息量,因此 top-K 个 token 蒸馏几乎避免了任何内存开销,且不会显著影响性能。
A.3 Off-Policy Training: Generalization to Logit-Level Losses
PPO 式裁剪结合截断重要性采样、裁剪更高(DAPO)、固定长度归一化(Dr.GRPO):

E Experiment Details
E.1 Technical setup
所有实验均在一台配备四块 NVIDIA GH200 GPU 的单节点上进行,总显存为 378GB。我们的环境基于 NVIDIA PyTorch 容器 nvcr.io/nvidia/pytorch:25.02-py3 构建,采用 CUDA 12.8 和 PyTorch v2.7.0。
我们的实现基于 verl 库。我们使用 PyTorch 全分片数据并行(FSDP2)进行分布式训练。对于 rollout 生成,我们采用了 vLLM,它能够在多 GPU 节点上高效地进行批量推理。
E.2 Hyperparameters
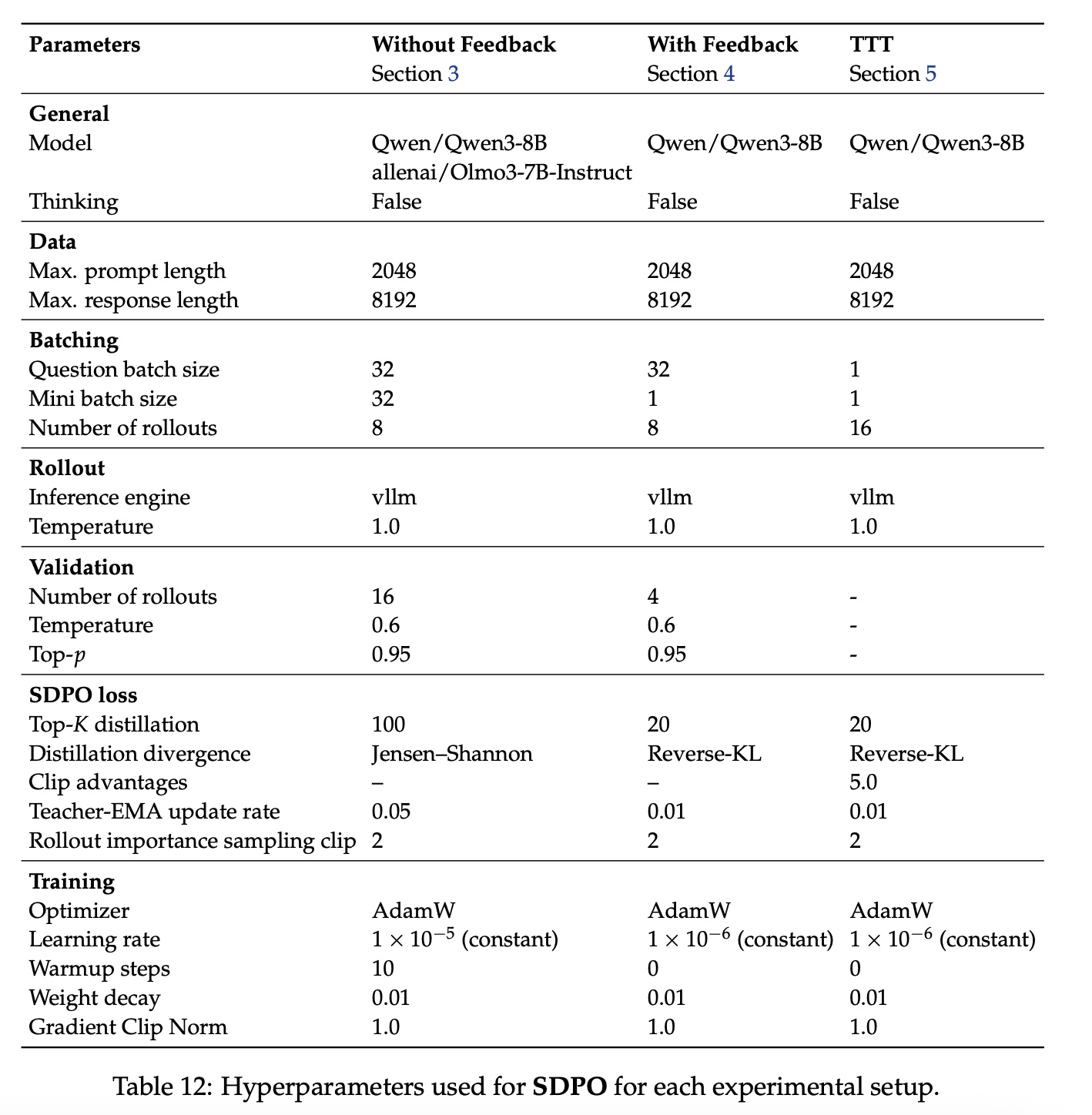
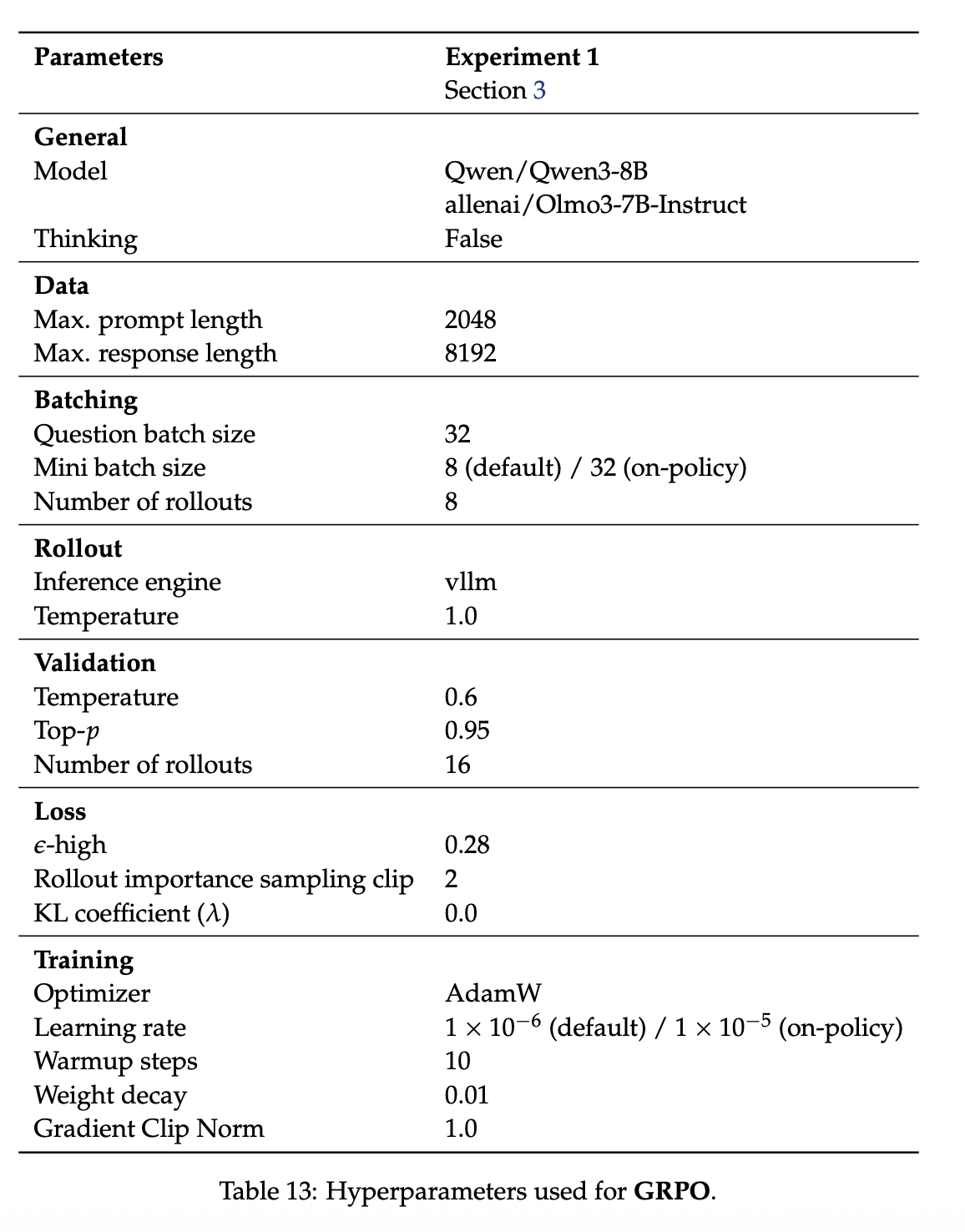
我们在表 12 中总结了 SDPO 使用的超参数,在表 13 中总结了 GRPO 使用的超参数。
E.2.1 Details on Hyperparameter Selection (Section 3)
对于第 3 节实验中的 GRPO,我们对学习率 和小 batch size 进行网格搜索。对于on-policy GRPO,我们在相同的学习率范围内进行搜索,同时将小 batch size 固定为 32。对于 SDPO,我们对 KL 函数的变体(前向 KL 函数、Jensen-Shannon 函数)、学习率 {10⁻⁵, 10⁻⁶} 和小批量大小 {8, 32} 进行网格搜索。对于每种方法(GRPO、策略内 GRPO 和 SDPO),我们选择一个超参数配置,使其在训练的前 5 小时内达到最高的验证准确率,该准确率在第 3 节中使用的所有数据集和模型上进行评估。我们在表 3 中进一步报告了针对每个模型和数据集分别选择最优超参数配置所获得的结果。